嘿,朋友们!这个问题我太有发言权了——作为一个整天折腾手机软件、没事就翻设置菜单的“野生数码控”,我最近刚好把微信小号这事儿研究了个透,你可能跟我一样,有时候工作群、家庭群、朋友群混在一起,消息炸得手机嗡嗡响,想换个清净又不想彻底“失联”,...
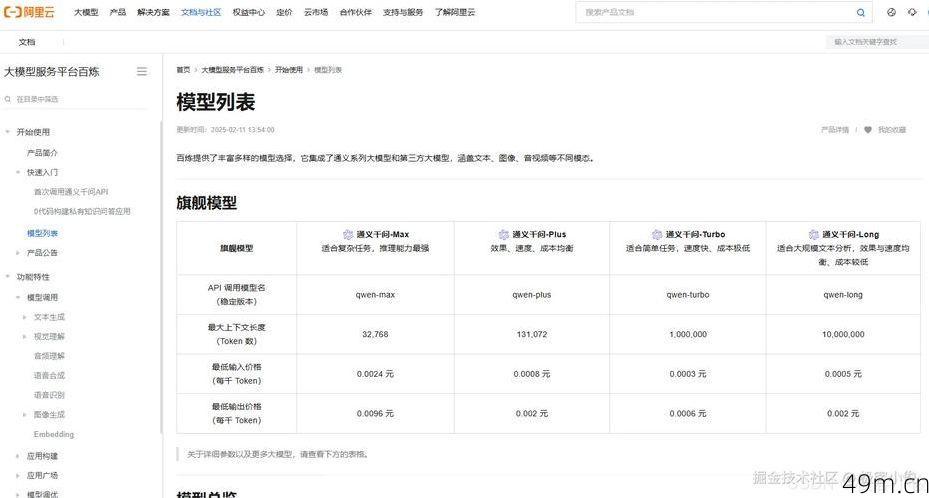
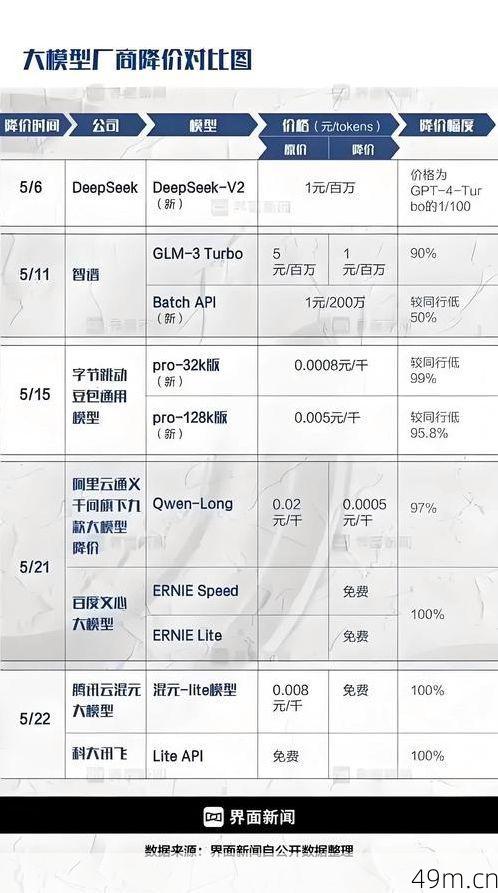
Tag:移动互联网科技新闻05月11日
作为一个网络和软件爱好者,我最近一直在疯狂测试GPT-5 API的各种功能,尤其是它的计费方式,说实话,刚开始接触的时候,我也被那些复杂的计费规则搞得一头雾水,但经过一段时间的摸索和实践,我发现其实只要掌握几个关键点,就能既高效又省钱地用上这个强大的工具,今天我就来和大家分享我的亲身经验,希望能帮你少走弯路,快速上手!
先来说说GPT-5 API的基本计费结构。GPT-5 API的计费核心是基于token usage的,就是你发送的请求和接收的响应中所包含的文本量会被转换成token数量,然后按token数收费,token是文本的基本单位,比如一个英文单词大约对应1-2个token,而中文汉字通常一个字符就算一个token,举个例子,如果你发送一条消息包含100个token,API返回的响应是200个token,那么总消耗就是300个token,计费通常是按每千token(1K token)来算的,价格会根据模型版本和用途略有不同,GPT-5的标准版本可能每1K token收费$0.01到$0.03,而更高级的版本或定制模型可能会贵一些。关键是要注意输入和输出都计费,所以优化请求内容能直接省钱。
我分享一些实际操作中的省钱技巧。优化你的提示词(prompt) 是降低token消耗的最有效方法,我刚开始用的时候,总是喜欢写很长的提示词,希望能得到更精准的响应,但后来发现这反而增加了不必要的开销,我最初会写:“请帮我生成一篇关于人工智能的文章,内容要包括历史、现状和未来趋势,字数在500字左右,语言要专业但易懂。” 这样的提示词可能消耗50-60个token,但经过优化,我改成:“写AI文章:历史、现状、500字,专业易懂。” 这只需要20个token左右,省了一半多!而且响应质量几乎没差别。尽量精简提示词,避免冗余描述,这样不仅能减少输入token,还能让API更快理解你的意图。
另一个实用技巧是利用流式响应(streaming)和缓存机制,如果你在开发一个应用,比如聊天机器人或内容生成工具,流式响应可以帮你按需获取数据,避免一次性消耗大量token,我在做一个项目时,需要生成长篇文章,我就设置了流式输出,每次只获取一段内容,这样我可以实时检查质量,如果发现不对就停止,避免浪费token。缓存常见请求结果也很重要,有些问题或命令是重复的(如“你好”或基本说明),我可以把API的响应存到本地数据库,下次直接调用缓存,而不是重新请求API,这为我省下了不少token,尤其是在高流量场景下。
关于计费的具体操作,我推荐大家定期监控使用情况,大多数API提供商(如OpenAI)都会提供仪表盘或API来查看实时消耗,我习惯每天登录控制台检查token usage,设置警报阈值,比如当每月使用量达到50%时发送邮件提醒,这样我能及时调整策略,避免超支。结合预算限制功能,你可以在API设置里设定每月最大支出,100,一旦接近这个值,API会自动限制或暂停请求,防止意外费用,这对我来说超级实用,因为有一次我忘了关测试脚本,一晚上跑了大量请求,差点超支,幸好有预算功能兜底。
聊聊如何选择适合的计费计划,GPT-5 API通常提供按需付费(pay-as-you-go)和订阅制两种方式。按需付费适合偶尔使用或测试阶段,比如我刚开始时就用这个,没有长期commitment,灵活又低成本,但如果你用量大,比如每月消耗超过100K token,订阅制可能更划算,因为它会提供折扣或固定费率,我建议先从小规模开始,用按需付费测试你的需求,然后根据数据决定是否升级。别忘了利用免费 tier 或试用期——很多平台会提供初始免费额度,比如前几个月免费使用一定量的token,这能帮你无风险地探索功能。
GPT-5 API的计费方式虽然看似复杂,但通过优化提示词、监控使用和选择合适计划,完全可以做到高效省钱,我希望我的经验能帮你更快上手,如果你有更多问题,欢迎在评论区交流——实践出真知,多试试才能找到最适合自己的方法!
嘿,各位玩机同好们!今天咱们来唠一个特别具体、但又可能让不少朋友头疼的问题:在233乐园成功注销账号后,怎么才能让系统“静悄悄”的,不向关联好友或设备发送任何通知? 我自己前阵子刚好因为想整理手头的应用账号,彻底注销了233乐园,并且成功实...
Tag:科技新闻