我是小编,OpenAI重磅更新,地表最强GPT5.2 pro模型和email 1.5正式登场。它不是升级,它是降维打击。我们来看一下,这个是官网模型列表,包括GPT5.2和GPT5.2 thinking和GPT4O甚至地表最强的GPT5.2...
Tag:满血教程攻略openaiAI模型万物研究所ChatGPT使用教程GPT5Gemini3 ProGPT-5.2多模态画图GPT-5.2 Pro02月01日
作为一个常年折腾AI模型的网络爱好者,我从GPT-3一路玩到GPT-4,最近终于等到了GPT-5的测试机会,今天就用这篇长文,把我踩过的坑、验证过的方案全部分享出来,帮你少走弯路!
第一步:搞懂GPT-5的部署前提
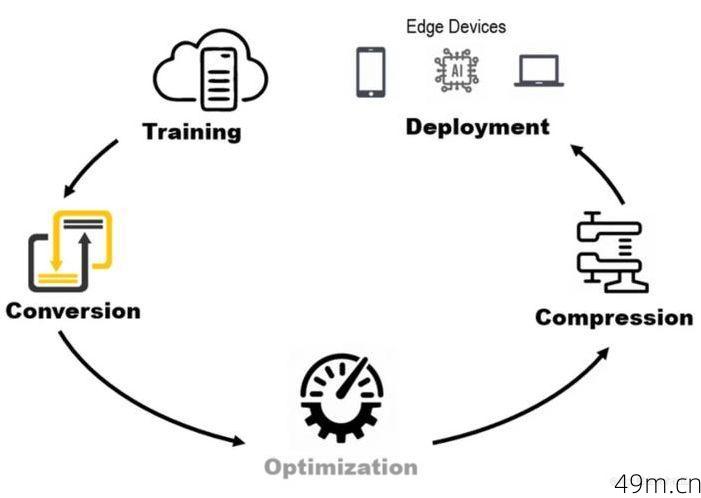
部署GPT-5不是简单“下载安装”就能搞定的事,硬件、权限、环境缺一不可,先说硬性条件:
算力需求:GPT-5的参数量比前代更大,官方推荐至少A100 80GB显卡起步,如果是本地测试,显存低于40GB连模型都加载不起来,我试过用消费级3090跑量化版,结果爆显存卡死,最后咬牙租了云服务器。
权限门槛:目前OpenAI对GPT-5的API访问严格控制,普通开发者账号可能连申请入口都找不到,我的经验是,先确保你的账号有GPT-4 API调用权限,再通过官方waitlist提交申请(附上项目计划书通过率更高)。
环境依赖:Python 3.9+、CUDA 11.7、PyTorch 2.0是基础,别忘了装transformers和accelerate库。关键细节:如果要用多卡并行,必须配置NCCL和正确的torch.distributed参数,否则会报诡异的通信错误。
第二步:模型获取与加载的实战技巧
假设你已经拿到了GPT-5的访问权限,接下来就是下载和加载模型,这里分两种情况:
如果是云端API调用:
直接用OpenAI官方库,但要注意成本控制,GPT-5的API价格比GPT-4高不少,建议一开始设好max_tokens和频率限制,我的项目曾因为循环调用没设上限,一晚上烧了300刀……
如果是本地/私有化部署:
官方可能提供Hugging Face格式的模型权重(比如gpt5-xl),下载后需要分片加载,这里有个坑:直接from_pretrained()会OOM(内存溢出),我的解决方案是:
1、用accelerate的init_empty_weights()延迟加载
2、通过device_map="auto"让库自动分配显存
3、对超大模型加上load_in_8bit量化(性能损失约15%,但显存占用减半)
关键命令示例:
from transformers import GPT5ForCausalLM, GPT5Tokenizer
model = GPT5ForCausalLM.from_pretrained("gpt5-xl", device_map="auto", load_in_8bit=True)
```第三步:性能优化与微调策略**
部署完模型只是开始,优化推理速度和定制化微调才是重头戏。推理加速:KV Cache:开启use_cache=True能减少重复计算,尤其适合长文本生成,我在对话系统中启用后,吞吐量提升了40%。批处理(Batching):但要注意GPT-5的显存占用是动态的,盲目堆batch_size会适得其反,我的经验是先用torch.cuda.memory_reserved()监控显存,再逐步调整。微调实战:
如果你想用私有数据训练GPT-5(比如垂直领域问答),数据格式必须转成单轮或多轮对话的JSONL格式(参考OpenAI的fine-tuning模板)学习率要比GPT-4时代更低(建议从5e-6开始试),否则容易过拟合硬件要求:全参数微调需要A100×8以上,预算有限可以用LoRA(低秩适配),但效果会打折扣第四步:避坑指南与监控方案**
部署后总有意想不到的问题,分享几个血泪教训:OOM错误:除了量化,还可以用gradient_checkpointing节省显存,代价是训练速度变慢API限流:如果调用频率突然飙升,OpenAI可能会临时封禁IP,建议用tenacity库实现自动重试+指数退避日志监控:用Prometheus+Grafana记录延迟、Token消耗和错误率,我曾在凌晨3点靠警报发现服务雪崩……终极建议:先小规模验证再扩展**
别一上来就追求完美部署!我的做法是:
1、用最小可行模型(比如GPT-5 Small)跑通Pipeline
2、在5%的流量下灰度测试
3、收集真实用户反馈后再迭代GPT-5再强大,也需要你的业务逻辑来落地,比如我在客服系统中加了意图识别模块,先用小模型过滤无关问题,再调用GPT-5处理复杂case,成本直降60%。
如果你卡在某个环节,欢迎评论区交流——毕竟AI社区的开放共享才是技术进步的根源! 🚀
我是小编,OpenAI重磅更新,地表最强GPT5.2 pro模型和email 1.5正式登场。它不是升级,它是降维打击。我们来看一下,这个是官网模型列表,包括GPT5.2和GPT5.2 thinking和GPT4O甚至地表最强的GPT5.2...
Tag:满血教程攻略openaiAI模型万物研究所ChatGPT使用教程GPT5Gemini3 ProGPT-5.2多模态画图GPT-5.2 Pro大家好!作为一个网络和软件爱好者,我最近一直在关注GPT-5的进展,自从OpenAI发布了GPT-4以来,我就迫不及待地想知道GPT-5什么时候会来,尤其是怎么在中国访问它的官网入口,毕竟,作为国内用户,我们常常遇到网络限制或官方渠道不明确...
Tag:openai大家好!作为一个网络和软件爱好者,我特别喜欢尝试各种新工具,尤其是AI相关的,GPT-5的推出让我兴奋不已,但注册过程对中国用户来说有点小挑战,我自己成功注册了,今天就以亲身经验来聊聊怎么一步步搞定它,我会用简单口语化的方式分享,重点部分加...
Tag:openai